If you've programmed for a living, then you've seen ugly code.
But where does it come from, and why doesn't it go away?
(Arguably the ugliness of code is subjective, but there are some things that most developers would agree make code more ugly in the sense of being harder to understand and harder to maintain. A somewhat perverse description of common methods of "uglification", as if you wanted to make your code uglier, can be found here.)
Making code "beautiful" may be too much to hope for, but when I see ugly code, my usual reaction is: can I make this code less ugly?
As a software developer, I feel sure that less ugly code is actually worth more, because the things that make code ugly are things that cause the following problems:
This feeling is summarised in the following diagram which illustrates code value as a function of ugliness:
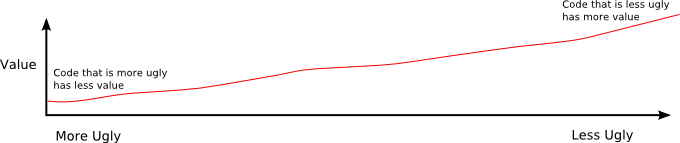
Figure 1: Graph of value as a function of code ugliness
Let's make the previous graph more specific, and locate our current code-base in a particular position on the ugliness dimension:

Figure 2: Graph of value showing location of existing code
Notice that the code is closer to the "more ugly" end (on the left) than it is to the "less ugly" end (on the right).
Notice also that the estimated value of the code would be increased if we could move it along in the direction of "less ugly".
But, uh oh! Something has happened:

Figure 3: Graph of value showing "value spike" at current code position
A value spike has arisen around the current position of the code.
Where did this value spike come from?
It arose because the code was tested. It was tested by the developer once it had compiled. It was tested formally by professional testers. In some cases, bugs were discovered, and fixed. And then the code was tested even more.
Testing code increases value the value of the code because it increases the probability that the code will correctly and reliably do all the things that it is intended to do.
The problem now is that we can't move our code to the right any more, because that would decrease the value of the code. That's because we would lose the value of the testing that has been done.

Figure 4: A decrease in value will occur if we attempt to make the code "less ugly", because we lose the value of all the testing that was done on the existing code-base
Of course, if we do decide to move to the right, and make our code less ugly, then we can eventually create a new value spike at the new location of the code-base. But this will require repeating all the effort put into creating the value spike while testing on the original code-base.
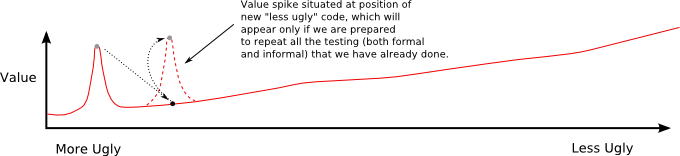
Figure 5: The value spike can be created again, but at the cost of repeating work already done
One reason we lose value when changing the code is that the testing was very specific to the current code-base. If we could make our testing less specific, and somehow applicable to hypothetical states of the code-base that don't yet exist, then we could "flatten" the spike, and make it easier to move away from the current state of ugliness.
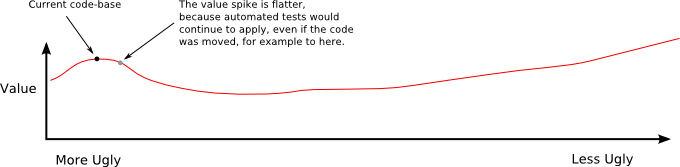
Figure 6: A flatter value spike, using testing methods which are potentially applicable to "improved" versions of the original current code-base
One thing that makes testing very specific is manual testing. If code is tested manually, for example by a tester using the application interactively, then that test only applies to the code that the test was run on. To make the testing less specific, we need to automate our testing.
Unfortunately, there are limits to how non-specific testing can be. Part of the theory of unit testing is to automate testing at a fine level of granularity. This is not a bad thing to do, but because of the granularity, the structure of unit tests is somewhat dependent on the structure of the code, and if the code is changed, the tests will have to be changed as well. (The value of unit tests is not completely lost when code changes incrementally, because incremental code changes can be made in tandem with incremental test code changes, but there is always some loss of work already done.)
However, even if some tests are automated, there will always be some other testing that is not automated. People can't help themselves. If the code is there, then it can be run, and it can be tested.
There is one form of testing which creates a very steep value spike, which can never be automated, and which is very difficult to replay. This form of testing is called production.
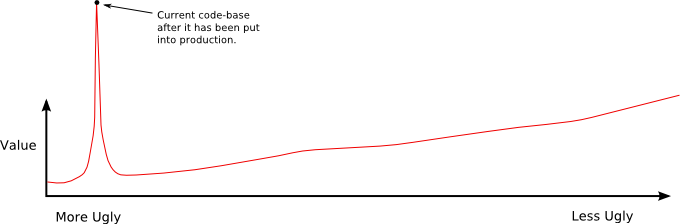
Figure 7: An even higher value spike, caused by code going into production
No matter how high the testing value spike is, if the graph increases to the right, then it might eventually reach a point which is higher than the current value, as shown in the following graph:

Figure 8: Move far enough to the right to get value higher than the current value
This seems like a way out of the impasse. But there are some potential problems with this "move-forever-to-the-right" plan.
The first problem is that it may require moving beyond the edge of the best current programming technologies, as shown here:
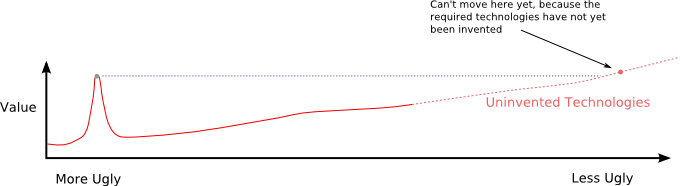
Figure 9: An attempt to make the code less ugly moves into territory of uninvented technologies
The second problem is that the point where value exceeds the current value is so far to the right that it ceases to be practical to move there incrementally, and in effect we are advocating abandonment and rewrite. In other words, the existing code might serve as a guide when constructing the new code, but there will not be any attempt to incrementally convert the existing ugly code into the newer less ugly code.
Although Plans A and B have their problems, there are some mitigating factors. It can be hard to "flatten" the spike, but on the other hand, if the code is sufficiently ugly, there is a limit as to how high the spike can rise. No matter how tested and debugged the code is, the sheer ugliness of the code can prevent it ever reaching beyond a certain level of functionality. It may become impossible to satisfy changing requirements. At which point the "abandon-and-rewrite" plan is likely to be put into effect.
The problem of "uninvented programming technology" can be overcome, especially these days, as easy-to-use parsing frameworks, such as Antlr and XText, make it practical to consider inventing your own programming language which is specifically tailored for the program you are writing. With a sufficient level of proficiency in language design, it should be possible to write application code which is as beautiful as it can possibly be, unconstrained by any existing programming languages or frameworks.
The value spike which locks us into ugly code is caused by testing, so it would seem that the best thing to do is not to test, or at least not to test until we have first made the code less ugly.
However, doing anything major "up-front" other than writing code and then testing it is considered against the best practices of modern "agile" iterative development. So there is some tension here. A possible compromise is to alternate between iterative development and iterative beautification, at least in the early stages of development.
A common refrain is: "We need to get stuff done now. Refactoring would be nice, but we'll have to do it later.".
The theory of the testing "value spike" shows that this is not going to happen. As time passes, the value spike can only grow higher, as more testing is done on the existing code-base. If it's worth refactoring ever, it's worth refactoring now.
To the developer who has to maintain and develop code, the negative value of ugly code seems obvious.
But most people do not read source code. Even developers will use open-source applications and never read the source code of those applications, caring only that the applications seem to run and do what they are meant to do without crashing.
For most people, the only measure of an application's value is its behaviour when tested. To these people, the testing value spike looks like this:

Figure 10: The graph of value, as it appears to non-developers
It follows that even the people who are paying for the application's development have no way of knowing whether the code is ugly or not, they have no way of knowing how the decisions they make about development processes affect the ugliness of the code, and they have no way of seeing what effect the ugliness of the code has on the long-term value of the code.
One could become resigned to the idea that only developers can recognise the hidden cost of ugly code, and that all applications ever written will suffer a slow and horrible death caused by the ugliness of the source code which is in turn caused by always giving priority to the pragmatic value of tested code versus the unverifiable aesthetic judgements of developers.
However, if this situation can be improved even a little bit, there are opportunities to develop better longer-lasting software which will be more competitive in the long term.
The easiest way for a developer to deal with management that ignores the importance of avoiding ugly code is for the developer to be management. The individual developer can freely apply their own standards to the code that they develop, and they can choose to refactor often and early, without anyone else telling them to "get the new features finished first so that they can be tested".
Unfortunately the commercial opportunities for individual developers are limited. Most of the money in commercial software development goes to the development of applications too large to be developed by one developer.
A developer-entrepeneur can apply their own aesthetic judgement to the source code of larger development projects, if they hire other developers to write the code, and spend most of their own time reviewing the code, raising any "ugly" code that they find as an issue to be fixed.
This approach requires other developers to accept the developer-entrepeneur's view of what constitutes "ugly" code, but this may be no worse that working for someone who doesn't care at all about code ugliness.
It also requires the developer-entrepreneur to have at least one non-developer business partner who can do all the other "business stuff" that entrepreneurs have to do, so that the developer-entrepreneur can concentrate on code review.
The most radical approach is to write source code intended to be read by non-developers. With this approach, the non-developer-entrepreneur can be responsible for code review, and can also involve the customer in the code review process.
To achieve this ambitious goal, of writing code that non-developers can read, will require a commitment to language-oriented programming, where the application is substantially programmed in a domain-specific language, i.e. a programming language specifically designed specifically for that application, and where the language and its implementation will be maintained along with the application code as requirements change.
Of course the code for an application written this way will still include some implementation code which is written in a general-purpose programming language, and which is not so easily read by a non-developer. But the aim will be to keep the amount of such implementation code to a minimum.